Gazprea Compiler (with Visualizer)
[Fall 2024] Building a complete compiler for an extinct language
Source: Closed Source
Background
Developed originally at IBM in Markham, ON for fast finance/business operations, the Gazprea programming language was adapted to be used as a project for the CMPUT415 Course at the University of Alberta. This course serves as a sort of capstone course, integrating various computing science skills including software design, programming, data structures, algorithms, theoretical computing, documentation, and even machine architecture. The specification for the version of gazprea used for the Fall 2024 semester can be found here.
Gazprea is built to be a quick, easy-to-write scripting language, but is compiled for maximum computing speed & efficiency. It uses four underlying variable types {integers, reals (floating-point decimals), characters, and booleans}, though they can also be implicitly inferred Each underlying primitive can be a scalar, vector, or matrix, and can be declared const. It also includes tuples, which are ordered (and optionally-named) collections of any number of arbitrary variable types.
Gazprea has all the same basic element-wise binary/unary operations between variables, as well as standard conditional/loop control flow statements and I/O functions. Gazprea has some composite operations that, when compiled, allow some impressive speed boosts. These composite operations include the generator and the filter expressions. which form vectors/matrices, and filters (respectively).

An example Gazprea program, which utilizes implicit variable types, basic generators, control flow, and output
Project
As the final assignment for the CMPUT415 Course, we were tasked with creating a compiler for the Gazprea programming language. Note that this was a group assignment, so all aspects of this project were created collaboratively in groups of four.
Our group's compiler is built in C++, using ANTLR4 to generate an LL(*) parser. Once the language is parsed, an Abstract Syntax Tree is built (that could be fully visualized with Graphviz (see below) anytime throughout the compilation pipeline), and used MLIR's C++ Interface/API to output MLIR Bytecode. This was then lowered to a raw LLVM Intermediate Representation (IR), which was them compiled to object files with llc (the LLVM Compiler).
Unfortunately, this project was an academic assignment, so I cannot disclose many more details about the specifics of the implementation.
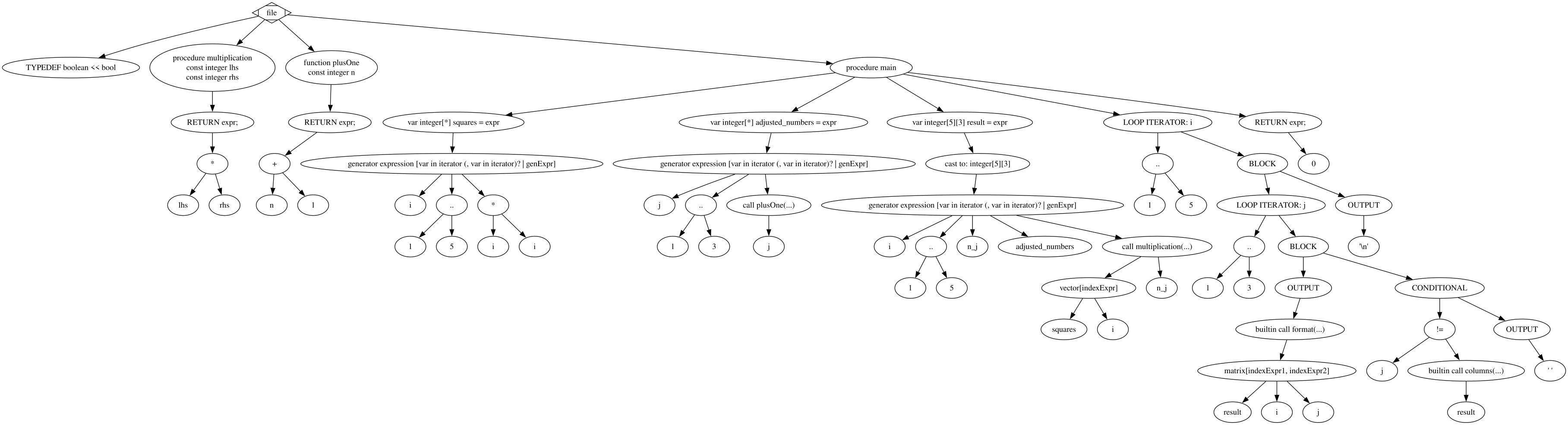
Example Graphviz output for example program above
Lessons Learned
- When projects involve others, exponentailly more work must be put into proper planning and organization
- Planning ahead is almost always easier than trying to reconcile issues after the fact
- Fully utilizing a proper issue tracker (e.g. GitHub Issues) massively improves speed/ease of communication
- Typically, a voice call (as opposed to text-based messaging) is easier, quicker, and more productive
- C++ has massively powerful OOP capabilities, but must be managed carefully
- Regarding file/directory organization, logical organization structures & file naming goes a long way
- When builfing class structures, having a carefully planned class hierarchy is a must
- Making a good/complete compiler is hard
- Figuring out the 'normal case' is easy, catching errors & handling edge/corner cases is hard
- Unit testing (and test-driven development (TDD)) is worth it, especially with good CI/CD capabilities
- We were able to have a dedicated CI/CD server, which always ensured changes were not counter-productive
- Having pre-written tests to "work towards" can be useful for knowing how changes need to be made